Mikel Rodriguez
I am a strategic technical advisor to national AI programs, focused on directing high-risk scientific and technical initiatives that address the country’s most consequential challenges. Over the past two decades, I’ve worked at the intersection of frontier AI, security, and real-world deployment—helping government and industry build systems capable of supporting ambitious national missions.
My focus is on ensuring that the most consequential applications of AI—those that shape the nation’s security, scientific leadership, and economic prosperity—are built on foundations that are secure, trustworthy, and aligned with the public good.
At Google DeepMind, I lead research within the Frontier & AGI Security Group, advancing methods to secure the next generation of highly capable AI systems. Previously, as a Managing Director at MITRE Labs, I built and led the Department of Defense’s AI Red Team and co-created ATLAS, the globally adopted framework for adversarial threats to machine learning. Across these roles, my work has emphasized the technical rigor, operational realism, and cross-sector collaboration required to deploy AI safely in high-stakes environments.
Before entering national-mission work, I earned my Ph.D. in computer vision at the University of Central Florida and completed a postdoctoral fellowship at INRIA/École Normale Supérieure in Paris.
A Framework for Evaluating Emerging Cyberattack Capabilities of AI
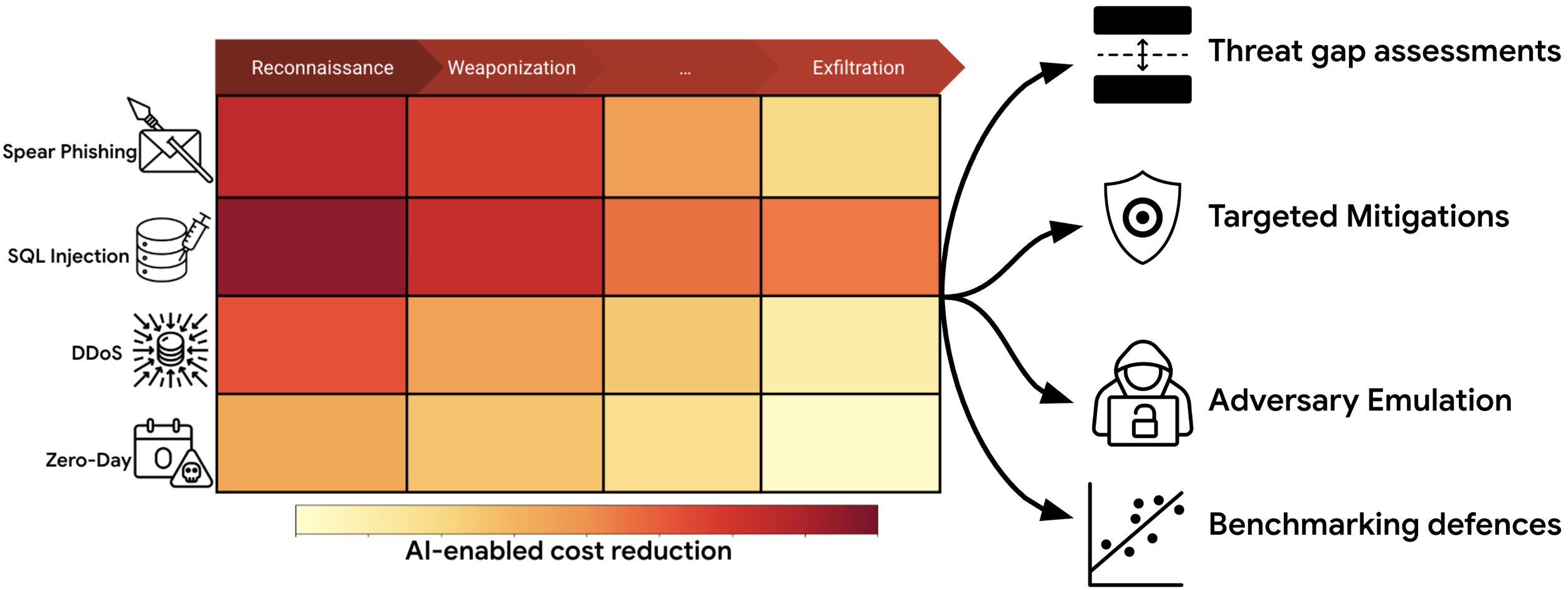
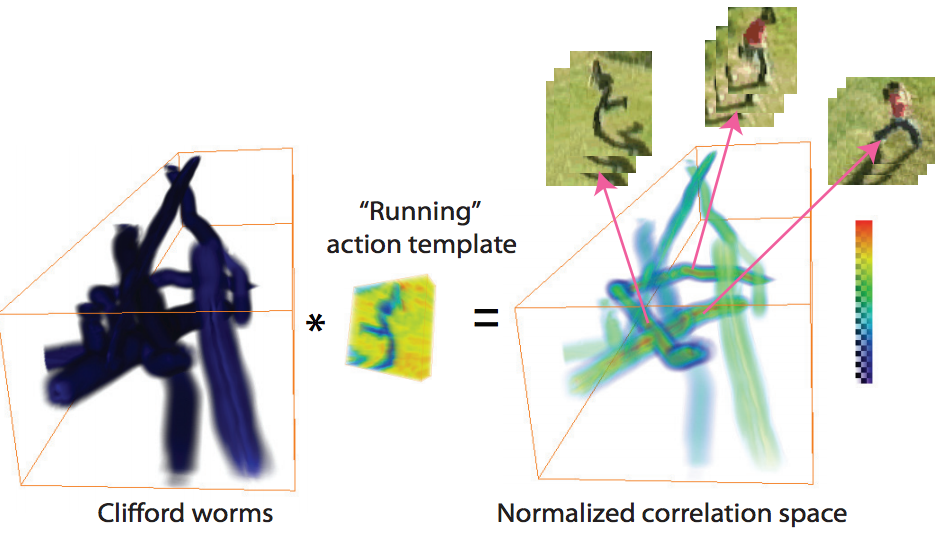
As frontier AI models become more capable, evaluating their potential to enable cyberattacks is crucial for ensuring the safe development of Artificial General Intelligence (AGI). Current cyber evaluation efforts are often ad-hoc, lacking systematic analysis of attack phases and guidance on targeted defenses. This work introduces a novel evaluation framework that addresses these limitations by: (1) examining the end-to-end attack chain, (2) identifying gaps in AI threat evaluation, and (3) helping defenders prioritize targeted mitigations and conduct AI-enabled adversary emulation for red teaming. Our approach adapts existing cyberattack chain frameworks for AI systems. We analyzed over 12,000 real-world instances of AI use in cyberattacks catalogued by Google's Threat Intelligence Group. Based on this analysis, we curated seven representative cyberattack chain archetypes and conducted a bottleneck analysis to pinpoint potential AI-driven cost disruptions. Our benchmark comprises 50 new challenges spanning various cyberattack phases. Using this benchmark, we devised targeted cybersecurity model evaluations, report on AI's potential to amplify offensive capabilities across specific attack phases, and offer recommendations for prioritizing defenses. We believe this represents the most comprehensive AI cyber risk evaluation framework published to date.

Responsible Reporting for Frontier AI Development
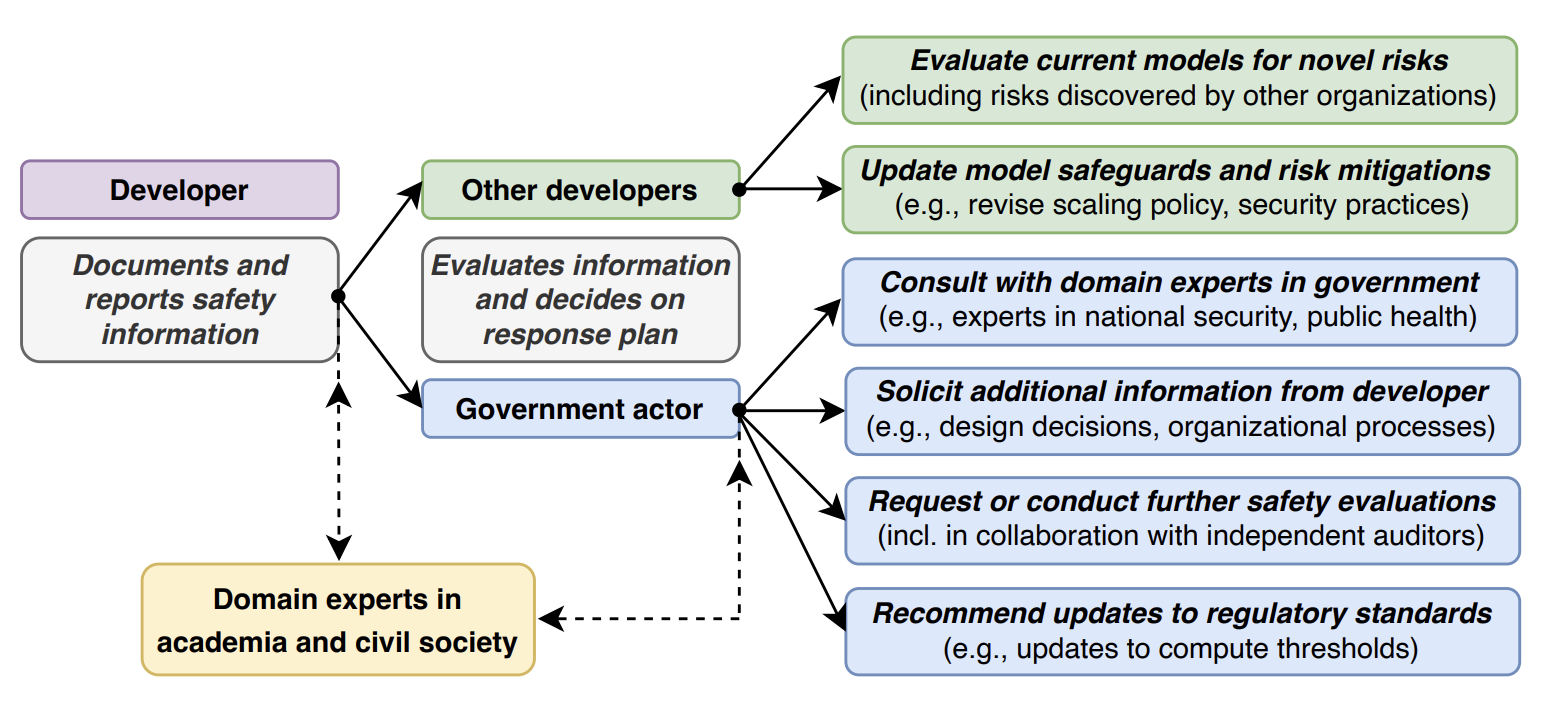
Mitigating the risks from frontier AI systems requires up-to-date and reliable information about those systems. Organizations that develop and deploy frontier systems have significant access to such information. By reporting safety-critical information to actors in government, industry, and civil society, these organizations could improve visibility into new and emerging risks posed by frontier systems. Equipped with this information, developers could make better informed decisions on risk management, while policymakers could design more targeted and robust regulatory infrastructure. We outline the key features of responsible reporting and propose mechanisms for implementing them in practice.
Holistic Safety and Responsibility Evaluations of Advanced AI Models
Safety and responsibility evaluations of advanced AI models are a critical but developing field of research and practice. In the development of Google DeepMind’s advanced AI models, we innovated on and applied a broad set of approaches to safety evaluation. In this report, we summarise and share elements of our evolving approach as well as lessons learned for a broad audience. Key lessons learned include: First, theoretical underpinnings and frameworks are invaluable to organise the breadth of risk domains, modalities, forms, metrics, and goals. Second, theory and practice of safety evaluation development each benefit from collaboration to clarify goals, methods and challenges, and facilitate the transfer of insights between different stakeholders and disciplines. Third, similar key methods, lessons, and institutions apply across the range of concerns in responsibility and safety – including established and emerging harms. For this reason it is important that a wide range of actors working on safety evaluation and safety research communities work together to develop, refine and implement novel evaluation approaches and best practices, rather than operating in silos. The report concludes with outlining the clear need to rapidly advance the science of evaluations, to integrate new evaluations into the development and governance of AI, to establish scientifically-grounded norms and standards, and to promote a robust evaluation ecosystem.
The ethics of advanced AI assistants: Malicious Uses

While advanced AI assistants have the potential to enhance cybersecurity, for example, by analysing large quantities of cyber-threat data to improve threat intelligence capabilities and engaging in automated incident-response, they also have the potential to benefit attackers, for example, through identification of system vulnerabilities and malicious code generation.
This chapter examines whether and in what respects advanced AI assistants are uniquely positioned to enable certain kinds of misuse and what mitigation strategies are available to address the emerging threats. We argue that AI assistants have the potential to empower malicious actors to achieve bad outcomes across three dimensions: first, offensive cyber operations, including malicious code generation and software vulnerability discovery; second, via adversarial attacks to exploit vulnerabilities in AI assistants, such as jailbreaking and prompt injection attacks; and third, via high-quality and potentially highly personalised content generation at scale. We conclude with a number of recommendations for mitigating these risks, including red teaming, post-deployment monitoring and responsible disclosure processes.
STAR: SocioTechnical Approach to Red Teaming Language Models

This research introduces STAR, a sociotechnical framework that improves on current best practices for red teaming safety of large language models. STAR makes two key contributions: it enhances steerability by generating parameterised instructions for human red teamers, leading to improved coverage of the risk surface. Parameterised instructions also provide more detailed insights into model failures at no increased cost. Second, STAR improves signal quality by matching demographics to assess harms for specific groups, resulting in more sensitive annotations. STAR further employs a novel step of arbitration to leverage diverse viewpoints and improve label reliability, treating disagreement not as noise but as a valuable contribution to signal quality.
Red Teaming Gemini: A Family of Highly Capable Multimodal Models
Within the AI community Red teaming can cover a broad range of topics from social harm to the more traditional cybersecurity definition. The term often refers to a process of probing AI systems and products for the identification of harmful capabilities, outputs, or infrastructural threats.
We build on and employ three types of red teaming techniques to test Gemini for a range of vulnerabilities and social harms.
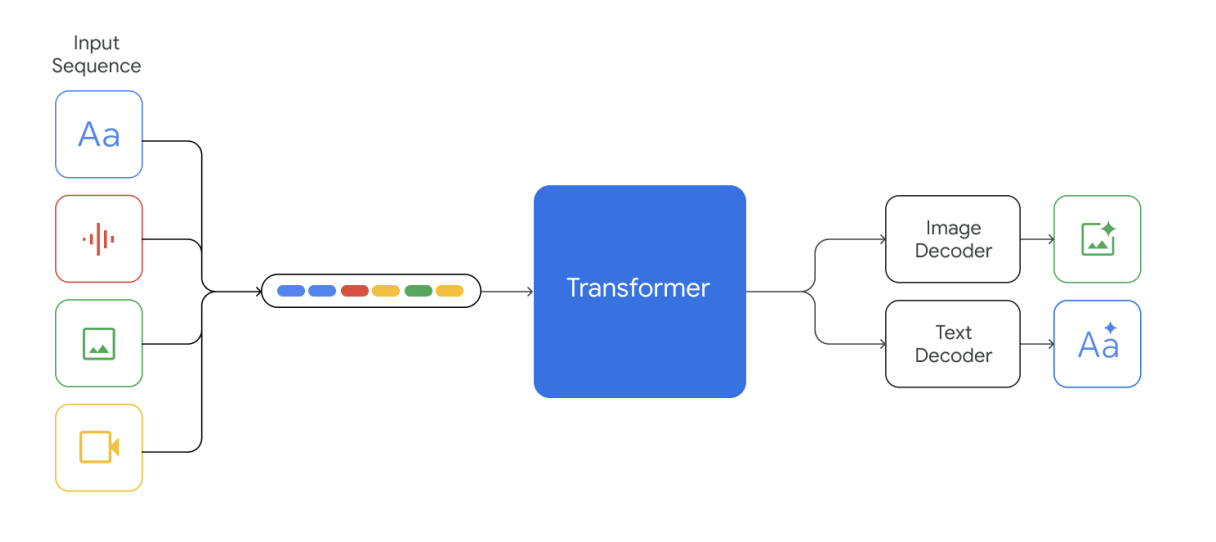
Anticipating and Managing Risks in Frontier AI Systems
The advent of more powerful AI systems such as large language models (LLMs) with more general-purpose capabilities has raised expectations that they will have significant societal impacts and create new governance challenges for policymakers. The rapid pace of development adds to the difficulty of managing these challenges. Policymakers will have to grapple with a new generation of AI-related risks, including the potential for AI to be used for malicious purposes, to disrupt or disable critical infrastructure, and to create new and unforeseen threats associated with the emergent capabilities of advanced AI.


Adversarial Machine Learning and Cybersecurity
Artificial intelligence systems are rapidly being deployed in all sectors of the economy, yet significant research has demonstrated that these systems can be vulnerable to a wide array of attacks. How different are these problems from more common cybersecurity vulnerabilities?
See the recent report produced in collaboration with the Center for Security and Emerging Technology and the Program on Geopolitics, Technology, and Governance at the Stanford Cyber Policy Center. We explore the extent to which AI vulnerabilities can be handled under standard cybersecurity processes, the barriers currently preventing the accurate sharing of information about AI vulnerabilities, legal issues associated with adversarial attacks on AI systems, and potential areas where government support could improve AI vulnerability management and mitigation.
AI Assurance: A Whole of Nation Challenge
Recently my focus has been on enabling the application of AI in high-stakes consequential environments. From healthcare to national security, recent advances in Artificial Intelligence (AI) can improve how we live our lives, modernize government operations, and increase national security. But these same technologies can create intended and unintended consequences for democratic processes, risks to mission critical systems, and risks to citizens. With rare exceptions, however, the idea of protecting AI systems was an afterthought until recently. Already, my team’s work at MITRE Labs has documented AI systems that can be susceptible to bias in their data, attacks involving evasion, data poisoning, model replication, and the exploitation of software flaws to deceive, manipulate, compromise, and render AI systems ineffective. More needs to be done to defend mitigate bias and defend against such attacks, secure the AI supply chain, and ensure the trustworthiness of AI systems so they perform as intended in mission-critical environments. AI’s potential will only be realized through collaborations that help produce reliable, resilient, fair, interpretable, privacy preserving, and secure technologies.
We are excited to announce MITRE ATLAS (Adversarial Threat Landscape for Artificial-Intelligence Systems). ATLAS is a knowledge base of adversary tactics, techniques, and case studies for machine learning (ML) systems based on real-world observations, demonstrations from ML red teams and security groups, and the state of the possible from academic research. ATLAS is modeled after the MITRE ATT&CK® framework and its tactics and techniques are complementary to those in ATT&CK.
ATLAS enables researchers to navigate the landscape of threats to machine learning systems. ML is increasingly used across a variety of industries. There are a growing number of vulnerabilities in ML, and its use increases the attack surface of existing systems. We developed ATLAS to raise awareness of these threats and present them in a way familiar to security researchers.

The ATLAS Matrix shows the progression of tactics used in attacks as columns from left to right, with ML techniques belonging to each tactic below

Along with Bryce Goodman, Ian Goodfellow and Tim Hwang we are excited to announce a NIPS workshop on machine deception. The workshop seeks to bring together the many technical researchers, policy experts, and social scientists working on different aspects of machine deception into conversation with one another. Our aim is to promote a greater awareness of the state of the research, and spark interdisciplinary collaborations as the field advances.